Comparing VPUs, GPUs, and FPGAs for Deep Learning Inference

Introduction
A key decision when getting started with deep learning for machine vision is what type of hardware will be used to perform inference. Graphics Processing Units (GPUs), Field Programmable Gate Arrays (FPGAs), and Vision Processing Units (VPUs) each have advantages and limitations which can influence your system design. This article will explore those properties and how to evaluate which platform is most suitable for your application.
GPU
The massively-parallel architecture of GPUs makes them ideal for accelerating deep learning inference. Nvidia has invested heavily to develop tools for enabling deep learning and inference to run on their CUDA (Compute Unified Device Architecture)cores. Google’s popular TensorFlow’s official GPU support is targeted for Nvidia’s CUDA enabled GPUs. Some GPUs have thousands of processor cores and are ideal for computationally demanding tasks like autonomous vehicle guidance as well as for training networks to be deployed to less powerful hardware. In terms of power consumption, GPUs are typically very high. The RTX 2080 requires 225W, while the Jetson TX2 consumes up to 15W. GPUs are also expensive. The RTX 2080 costs $800 USD.
FPGA
FPGAs are widely used across the used machine vision industry. Most machine vision cameras and frame grabbers are based on FPGAs. FPGAs represent the middle ground between the flexibility and programmability of software running on a general-purpose CPU and the speed and power efficiency of a custom designed Application Specific Integrated Circuit (ASIC). An Intel®™ Aria 10 FPGA-based PCIe Vision Accelerator card consumes up to 60W of power and is available for $1500.
A downside of using FPGAs is that FPGA programming is highly specialized skill. Developing neural networks for FPGA’s is complex and time consuming. While developers can use tools from third parties to help simplify tasks, these tools are often expensive and can lock users into closed ecosystems of proprietary technology.
VPU
Vision Processing Units are a type of System-On-Chip (SOC) designed for acquisition and interpretation of visual information. They are targeted toward mobile applications and are optimized for small size and power efficiency. The Intel® Movidius™ Myriad™ 2 VPU is a perfect example of this and it can interface with a CMOS Image Sensor (CIS), pre-process the captured image data, then pass the resulting images though a pre-trained neural network, and output a result while consuming less than 1 W of power. Intel’s Myriad VPUs do this by combining traditional CPU cores and vector processing cores to accelerate the highly branching logic typical of deep neural networks.
VPUs are excellent for embedded applications. While less powerful than GPUs, their small size and power efficiency enable them to be designed into extremely small packages. For example, the upcoming FLIR Firefly camera, with its embedded Myriad 2 VPU, is less than half the volume of a standard “Ice-cube” machine vision camera. VPUs’ power efficiency makes them perfect for handheld, mobile or drone-mounted devices where long battery life is highly desirable.
Intel has created an open ecosystem for their Movidius Myriad VPUs, enabling users to use the deep learning framework and toolchain of their choice. The Intel Neural Compute Stick has a USB interface and costs $80.
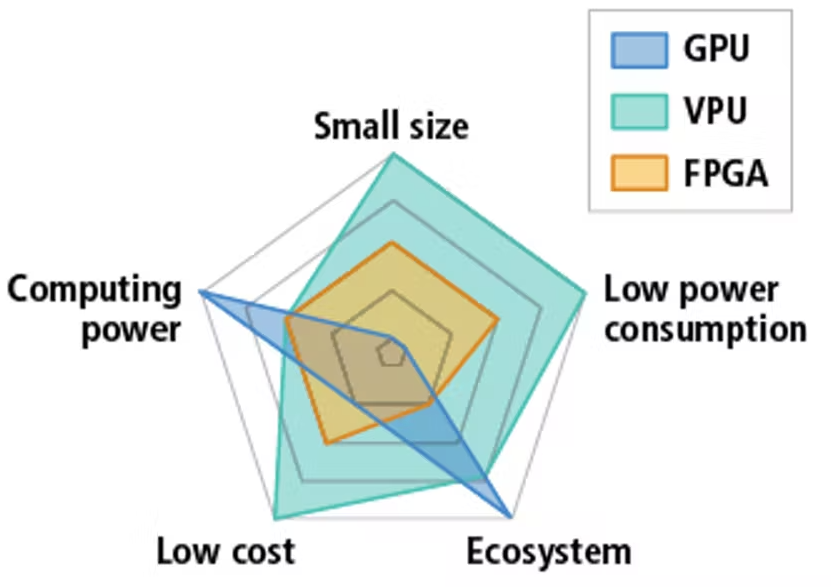
Fig 1. Relative performance of common hardware used to accelerate inference
Estimating performance of different hardware
Differences in architecture between GPUs, SOCs and VPUs make performance comparisons using Floating-Point Operations per Second (FLOPS) values of little practical value. Comparing published inference time data can be a useful starting point, however inference time alone may be misleading. While the Inference time on a single frame may be faster on the Intel Movidius Myriad 2 than the Nvidia Jetson TX2, the TX2 can process multiple frames at once, yielding greater throughput. The TX2 can perform other computing tasks simultaneously, while the Myriad 2 can not. Today, there is no easy way to compare without testing.
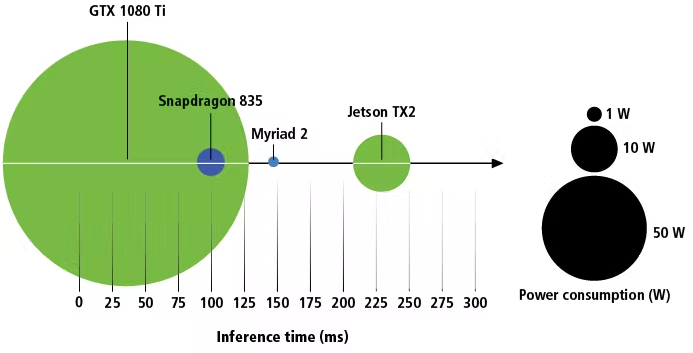
Fig 2. Power consumption vs Single frame inference Time
Conclusion
Prior to selecting the hardware which will power an inference enabled machine vision system, designers should conduct tests to determine the accuracy and speed required for their application. These parameters will determine the characteristics of the neural network which will be required and the hardware it can be deployed to.
Related Articles
-
 Embedded Vision
Embedded Vision
Streaming 4x Cameras with Small Carrier Board: Fast Prototype
Read the Story -
 Embedded Vision
Embedded Vision
How to Build a Custom Embedded Stereo System for Depth Perception
Learn more -
 Embedded Vision
Embedded Vision
Guide for Integrating Board Level Cameras
Read the Story