Neural Networks Supported by Neuro on the Firefly-DL
Applicable products
Firefly®-DL
Application note description
This application note describes neural networks supported by Neuro on the Firefly-DL camera.
Related articles
- Tips for Creating Training Data for Deep Learning and Neural Networks
- Troubleshooting Neural Network Conversion Errors
- Getting Started with Firefly-DL in Linux
- Getting Started with Firefly-DL in Windows
Convolutional Neural Networks (CNN)
CNNs are a class of neural networks often used to analyze images for certain characteristics. They can determine which category an image belongs to or which objects are in an image. The Firefly-DL supports a number of different CNN model architectures that can be trained using the Tensorflow or Caffe machine learning frameworks.
The Firefly-DL supports two different types of neural networks: classification and object detection.
Classification indicates the best option from a list of predetermined options; the camera gives a percentage that determines the likelihood of the current image being one of the classes it has been trained to recognize. On the Firefly-DL, classification can be done with Tensorflow networks and Caffe networks.
Object detection also indicates the most likely class given a set of predetermined options.; on top of that, object detection provides a location within the image (in the form of a "bounding box" surrounding the class), and can detect multiple objects in the same image. Note that object detection can only be done with Caffe networks in the Firefly-DL.
Inference time, inference data, and frame rate
It takes time to do inference on an image, however by default, this will not reduce your maximum frame rate. For example, after loading a classification inference network onto the camera, the inference data for this particular classification network is updated at approximately 15 frames-per-second on the FFY-U3-16S2M. If the frame rate is 60 fps, the camera captures at 60 fps, and the inference data is updated every four frames captured. You can determine which frame is associated with a particular inference result by enabling the Inference Frame ID chunk data. See example code "Inference" which comes included with the Spinnaker SDK for details on how to set this up in code.
If you want to limit frame rate so that every frame contains new inference data, in SpinView's Feature tab, set:
- Trigger Selector to Frame Start
- Trigger Source to Inference Ready
- Trigger Mode to On.
How often inference data is updated is determined by:
- exposure time - how long it takes to expose an image
- scaling time - how long it takes to rescale an image to the neural networks desired input dimensions
- inference time - how long it takes to do inference on an image
- readout time - how long it takes to transfer an image from the sensor to the on camera frame buffer
The most important factor is the inference time. We documented the inference time for each neural network we tested, shown below.
Tested and supported CNNs
- SSD Mobilenet detects 20 objects (see label file).
| Converted Model |
Converted Model Size (MB) |
Firefly-DL Inference Time (ms) |
Model Source |
Input Image Dimensions (width/height) |
|---|---|---|---|---|
| SSD Mobilenet v1 (object detection) |
12 | 167 | PROTOTXT CAFFEMODEL |
300 |
Note: image dimensions refers to what training data should be resized to before being fed into the neural network. The actual training data can be of similar size, or much larger.
| Converted Model |
Converted Model Size (MB) |
Inference Time for Mono and Colour Firefly-DL (mono ms / colour ms) |
Model Source |
Input Image Dimensions (width/height) |
|---|---|---|---|---|
| Mobilenetv1_1.0_224 | 8.3 | 81 / 83 | v1_1.0_224 | 224 |
| Mobilenetv1_1.0_192 | 8.3 | 58 / 60 | v1_1.0_192 | 192 |
| Mobilenetv1_1.0_160 | 8.3 | 47 / 47 | v1_1.0_160 | 160 |
| Mobilenetv1_1.0_128 | 8.3 | 34 / 34 | v1_1.0_128 | 128 |
| Mobilenetv1_0.75_224 | 5 | 54 / 59 | v1_0.75_224 | 224 |
| Mobilenetv1_0.75_192 | 5 | 39 / 43 | v1_0.75_192 | 192 |
| Mobilenetv1_0.75_160 | 5 | 34 / 36 | v1_0.75_160 | 160 |
| Mobilenetv1_0.75_128 | 5 | 24 / 26 | v1_0.75_128 | 128 |
| Mobilenetv1_0.5_224 | 2.6 | 32 / 38 | v1_0.5_224 | 224 |
| Mobilenetv1_0.5_192 | 2.6 | 25 / 31 | v1_0.5_192 | 192 |
| Mobilenetv1_0.5_160 | 2.6 | 20 / 23 | v1_0.5_160 | 160 |
| Mobilenetv1_0.5_128 | 2.6 | 15 / 18 | v1_0.5_128 | 128 |
| Mobilenetv1_0.25_224 | 0.9 | 19 / 27 | v1_0.25_224 | 224 |
| Mobilenetv1_0.25_192 | 0.9 | 15 / 20 | v1_0.25_198 | 198 |
| Mobilenetv1_0.25_160 | 0.9 | 13 / 16 | v1_0.25_160 | 160 |
| Mobilenetv1_0.25_128 | 0.9 | 10 / 12 | v1_0.25_128 | 128 |
| Inception v1 | 13 | 231 / 220 | Inception_v1_2016* | 224 |
| *The Inception model source differs from the other model sources in format (cpkt file), which is currently not convertible using the NeuroUtility. This functionality will be provided in an upcoming release of NeuroUtility. |
Note: image dimensions refers to what training data should be resized to before being fed into the neural network. The actual training data can be of similar size, or much larger.
Mobilenet's file names indicate the channels and input size as follows: Mobilnetv1_channels_inputsize
Channels indicates the proportion of channels used between each layer in the network. 1.0 = maximum number of channels, 0.75 = 75% of channels. A large number of channels is more accurate, has a larger file size and a longer inference time.
Inputsize is the width and height of the input image. Networks that take larger images are more accurate but have a longer inference time.
It should also be noted that Mean/Scalar (for each color channel) needs to be defined for each neural network as well. Using the equation found below, Mean/Scalar values normalize input data before feeding to the neural network.
Preprocessed Frame = (PixelValue - Mean)/ Scalar
For the models we have listed here, they all use a standard value of 127.5 for each mean/scaler color channel value. For Neuro Utility, the default value for mean/scalar is also set to 127.5, and can be modified in the setup page.
Which CNN should I use?
Any of the neural network types listed above can be used by the Firefly-DL camera, once converted. Each one can be retrained to classify different categories to fit your application requirements. The longer the inference time, the higher confidence value you can expect from your retrained network.
For object detection (rather than classification), FLIR recommends SSD Mobilenet.
Unsupported CNNs
The Firefly-DL has a size limit of approximately 15 MB for neural network graph files. The following neural networks were tested and found to produce graph files that were too large for the camera:
- Facenet based on inception-resnet-v1
- inception-v2
- inception-v3
- inception-v4
- inception resnet v2
- TinyYolo v2
- Vgg16
- Alexnet
- Resnet 18
- Resnet 50
- TinyYolo v1
Additionally, Tensorflow object detection is not supported.
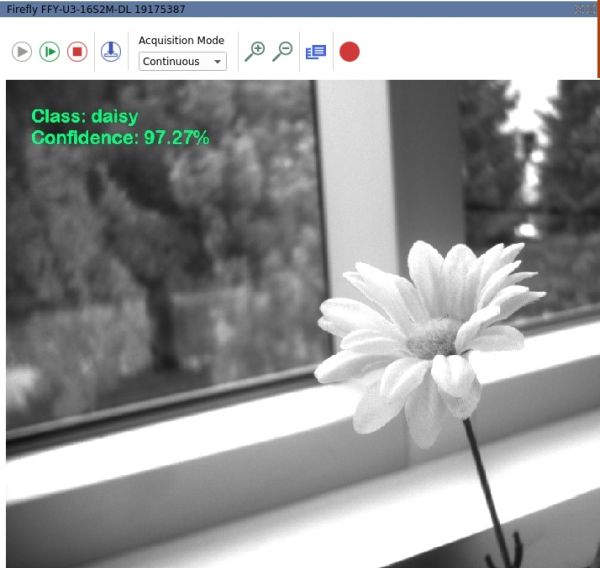
Test CNN using SpinView
Upload inference network file
- Open SpinView, select the camera, then switch to the file access tab.
- From the drop-down menu, select Inference Network.
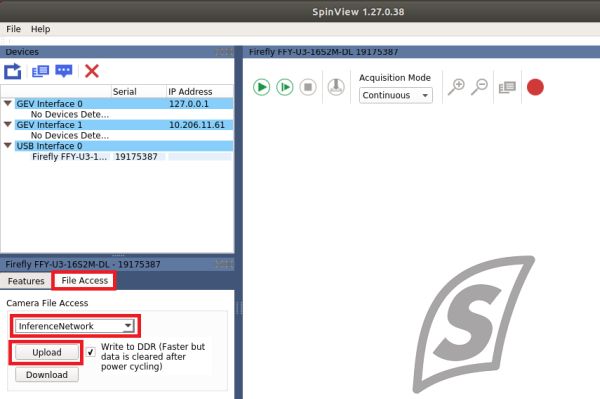
- Click Upload and navigate to your network inference file location. Selecting the file begins the upload.
Display inference data
- Open SpinView, select the camera, then switch to the features tab.
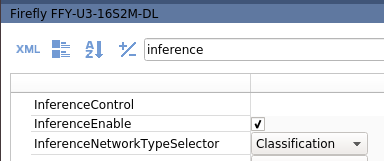
- Search for "inference".
Ensure network type selector is set to your inference network file's type. - Select Inference Enable.
- Search for "chunk".
- Select Chunk Mode Active.
For a classification network, select Chunk Enable for both Inference Result and Inference Confidence.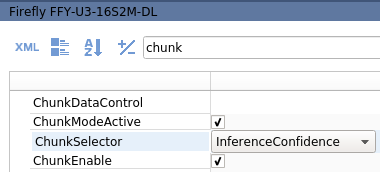
For a detection network, select Inference Bounding Box Result. - Right-click on the streaming window, and select Enable Inference Label.
- Click Configure inference label.
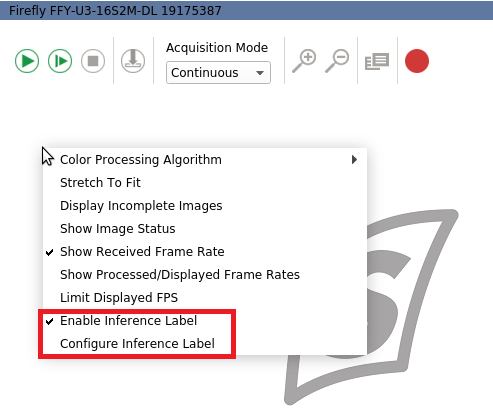
- In the pop up window, click browse to navigate to the label text file and click Apply.
- Click on the green play icon to start camera acquisition.
Related Articles
-
 Application Note
Application Note
Getting Started with Firefly-DL in Linux
Read the Story -
Deep Learning
Tips for Creating Training Data for Deep Learning Neural Networks
Read the Story -
Deep Learning
Troubleshooting Neural Network Conversion Errors
Read the Story