Tips for Creating Training Data for Deep Learning Neural Networks
Applicable products
Firefly®-DL
Application note description
This application note describes how to develop a dataset for classifying and sorting images into categories, which is the best starting point for users new to deep learning.
Related articles
- Getting Started with Firefly-DL in Linux
- Getting Started with Firefly-DL in Windows
- Neural Networks Supported by the Firefly-DL
- Troubleshooting Neural Network Conversion Errors
Preparing for use
Before you use your camera, we recommend that you are aware of the following resources:
- Camera Reference for the camera—HTML document containing specifications, EMVA imaging, installation guide, and technical reference for the camera model. Replace <PART-NUMBER> with your model's part number:
http://softwareservices.flir.com/<PART-NUMBER>/latest/Model/Readme.html
For example:
http://softwareservices.flir.com/FFY-U3-16S2M-DL/latest/Model/Readme.html - Getting Started Manual for the camera—provides information on installing components and software needed to run the camera.
- Technical Reference for the camera—provides information on the camera’s specifications, features and operations, as well as imaging and acquisition controls.
- Firmware updates—ensure you are using the most up-to-date firmware for the camera to take advantage of improvements and fixes.
- Tech Insights—Subscribe to our bi-monthly email updates containing information on new knowledge base articles, new firmware and software releases, and Product Change Notices (PCN).
Overview
One of the most important factors to retraining an efficient deep learning neural network is the training data provided. A high-quality training dataset improves inference accuracy and flexibility.
How much training data is needed?
The amount of training data required depends on the following factors:
- Number of data classes to be distinguished
- For example, Apple, Leaf, Branch
- Similarity of classes to be distinguished
- For example, Apple versus Pear is more complex than Apple versus Leaf
- Intended variance within each class
- For example, apples of different colors and shapes, for more robustness against variations in the real-life application scenario.
- Unwanted variance in the image data
- For example, noise, white balance differences, brightness, contrast, object size, or viewing angle
For a simple application a few hundred images may be enough to deliver acceptable results, while more complex applications could require tens of thousands. The best way to determine your training data requirements is to gather data and test your model with it. Your network eventually reaches a point where additional data does not improve model accuracy. It is unlikely your model will achieve 100% accuracy no matter how big your training dataset is.
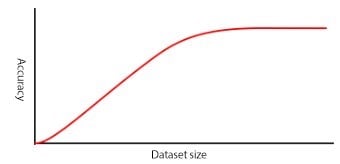
Minimize differences between training and production data
Capturing images with the same cameras, optics, and lighting as the future production system eliminates the need to compensate for differences in geometry, illumination, and spectral response between training and live image data. If you are planning on having your application only work in an indoor setting with consistent lighting, your training data only needs to cover that setup. To make your retrained model more flexible, more training data for different scenarios would be essential.
Use controlled environments
A good training dataset includes examples of variation where expected and minimizes variance where it can be eliminated by system design. For example, inspecting apples while they are still on the tree is much more complex than inspecting the same apples on a conveyor belt. The outdoor system needs training to recognize apples at different distances, orientations, and angles, and must account for changing lighting and weather conditions. A model that performs consistently requires a very large dataset.
Taking images of apples in a controlled environment allows system designers to eliminate many sources of variance and achieve high-accuracy inference using a much smaller dataset.
| Controlled Environment | Uncontrolled Environment |
 |
 |
Improve results with accurate categories
Images must represent the categories to which they belong. Inaccurate or noisy images are a common problem with datasets assembled using internet image searches.
| Well selected | Poorly selected |
 |
 |
In either a classification or object detection neural network, every class or object you want to detect needs to have its own category. If you are looking for flaws in an apple, you would have training data for good apples, and separate training data for bad apples.
In our Getting Started with Firefly Deep Learning application notes, the classification example script uses the folder structure to categorize images. Each category has its own folder with each folder being filled with jpeg images of that category/class. The individual image names don’t matter.
Properly size images
For the neural networks we have tested, the expected width/height of images can range from 28 pixels to 300. Any training data that is provided is eventually resized to fit the required input dimensions/shape for that neural network. Having training data similar to or greater than your desired neural network requirements is essential for getting the best results.
It can be helpful to save images larger than your neural network's requirements (for example saving images using the full resolution of your Firefly-DL camera). as it would allow for more flexibility when implementing augmentation (cropping, rotation, scaling, etc.), which would all occur before the image is resized.
![]()
Related Articles
-
 Application Note
Application Note
Getting Started with Firefly-DL in Linux
Read the Story -
Deep Learning
Neural Networks Supported by Neuro on the Firefly-DL
Read the Story -
Deep Learning
Troubleshooting Neural Network Conversion Errors
Read the Story